随着大数据技术的发展和互联网移动应用的兴起,各类型数据开始显现,包括:语音、图片、视频,特别是社交产生的各种文本越来越复杂,数据的处理产生了巨大变化。
跟随技术的发展,CSDN大数据的峰会已经办了10年,大数据技术领域经过十年的变化已经落地到各行各业。
在BDTC 2017大会的现场,CSDN与国内知名金融级数据库厂商SequoiaDB 巨杉数据库,解决方案总监彭旸一起,就大数据行业的发展及技术趋势进行了深入的探讨。
首先,彭旸分三个方面阐述了金融行业在大数据时代的机遇和挑战
需求驱动技术发展。金融业务的“互联网化”趋势不可逆转,造成数据爆炸增长,数据相关的业务发展速度,而且觉得压力非常大。对于企业来说,需要从需求驱动来推动技术的演进,紧跟数据业务的变化,而不仅是从技术概念是否“新潮”来理解。
监管压力。银行和金融行业在技术上的监管十分严厉,因此对于技术和业务的成熟度稳定性要求是所有行业最严格的。同时,金融行业不像互联网企业,是从很轻量级的水平发展,存在业务过渡期。金融企业大多是在庞大的体系背景下考虑数据库产品的可靠性问题。它不能用一个团队或者一个产品去试错。
成本与投入。互联网企业的业务模型往往很有穿透力,出错成本低,同时对于技术的投入既是与自己的产品和业务更多相关;金融行业,更看重产品的产品化程度和企业级服务,因为IT技术投入和人员规模所限。而像证券、银行选择数据库产品的时候,是否成熟、产品化,是不是得到原厂的支持这是第一看中的,然后才看中的是将来在新业务当中能不能自主研发突破。
不久前,巨杉和阿里云首次代表中国的数据库产品入选了国际知名行业分析机构Gartner的数据库行业年度报告,对于整个业界的认可,彭旸解释说,Gartner从几个方面来衡量:
第一, 首先是数据库产品的发展是否符合Gartner对于整个数据库发展的预期,是否在技术上领先且有过人之处。
第二, 用户特别是企业级用户的使用情况和市场分布。简单说企业的技术点和行业方向,是不是具有普遍意义,是否能解决共性的问题,还是仅仅解决某一家企业自身的特殊问题。客户和市场觉得了企业未来的发展。
第三, 国际化程度。同样也是代表对市场规模的预期,如应用场景除了中国以外国际上有没有相关的市场覆盖,用户分布在世界多少个大区域等。
当然还有一点也很看重,就是是否有自己的核心技术。
所以,Gartner报告的入选标准不仅是从技术层面分析,还会从一个企业、产品的整体健康程度来看。对于入围企业来讲,不仅要通过技术创新的选拔,更需要产品处于成熟期的发展阶段。当然今年3家中国产品第一次进入Gartner“法眼”,也可以说是国内数据库行业的一个重要里程碑,也是“中国原创力量”全球化上的一个里程碑。
Gartner入选数据库推荐报告产品名单,巨杉是首批三家中国厂商之一:
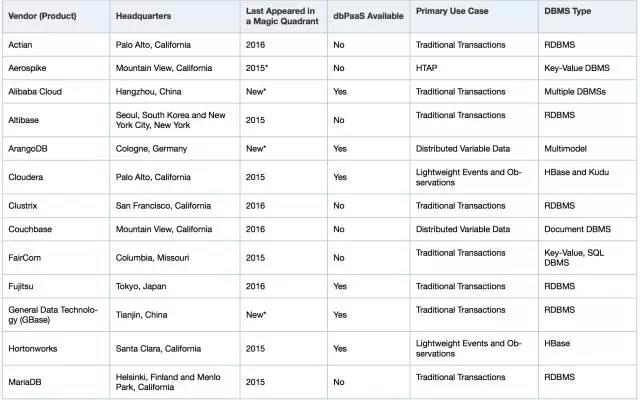
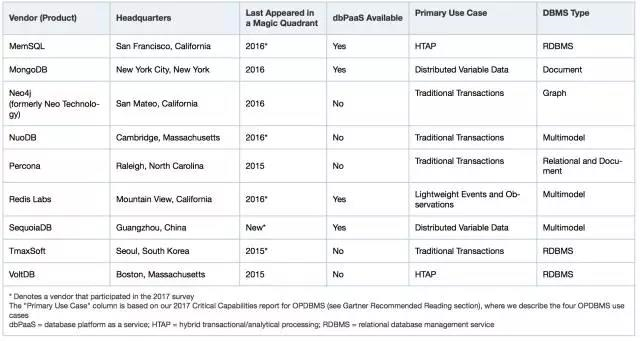
“数据库行业从来不是一蹴而就的,没有一家公司现在想做就可以做成。现在的数据库,能做成产品的至少6年以上的沉淀,一个不具备6年打磨的产品很难成为主流数据库产品。”
为什么强调“金融级”,彭旸认为,如同上文提到的金融行业的需求和痛点,“金融级”代表了产品在成熟度、稳定性、数据量、安全性、性能和易用性等方面达到金融行业要求的产品。“金融级”可以说就是产品的最高标准!
以金融企业为首的企业用户的在数据体量、技术难度、复杂度远远、安全性等超出一般企业,传统的单点数据架构已经不能解决现有问题,金融行业等实际需求促使着分布式概念的产生。这就催生了大型企业用户“分布式架构转型”的要求出现。这其中,大家熟知Hadoop架构更多代表的是分析型场景,另一边,对于更多在线、高并发等“操作型”场景,则需要新一代分布式数据库来解决。
巨杉在分布式技术的一些特性首先就是数据的分区分布,既可以按照业务划分分区分布也可以按照地理位置实现分布式管理,比如有的数据是来自上海有些来自北京,数据就可以按区分划分,提升对应地域的响应;其次,强调并发性,巨杉将一些组件高速的分布在各个节点,让它同时进行计算和数据处理,在实际企业生产中,并发性可以轻松达到几万。
最后,很多传统企业刚刚接触分布式技术,很难从业务架构中理解到这些层面。巨杉已花费大量时间为客户做架构、业务层面的数据梳理、预先数据定义和规划。这些工作对于数据库的结构逻辑整理和归档,是非常必要的。这个也是我们基于多年企业级市场成功经验结合到产品服务中的。
传统单点数据库的可靠、稳定性无可非议的优秀。过去,银行需要知道自己未来有多少的用户,要面对多大的市场,单点数据库需要预估好规模。但未来,银行会更贴近C端,中间环节越来越少。其中,数据量变得很大,业务也会大面积变化,银行很难从一开始去预估需求量大小,如果说按照传统的单点规划,成本将非常高。彭旸认为,分布式数据库可以通过网络并行计算不断的去增加弹性,未来银行可以根据业务需求来增减支出,这个将是与传统单点数据库最大的区别之一。
针对金融分布式架构的发展趋势话题,彭旸认为,未来分布式架构层将迎来更多的融合,底层的整体架构类型不会像以前那么多。虽然架构融合,但是工具上会有百花齐放,今天神经网络算法很先进,明天可能就被颠覆,这些都会造成工具和算法的大面积变化。对于银行来说,体系上肯定会趋于稳定,但在工具和应用层面还是会有大量的创新。
就大数据来说,像数据产生、治理、注入、实时数据风险预估等操作性很重要的技术范畴。巨杉数据库作为操作型数据平台,重在在线业务和操作方面,可以满足客户正常数据追问、数据实时处理、交易事务型数据处理、高并发的读写访问等需求。
在过去的几十年中,受限于传统数据库的存储与计算能力,企业中不同业务部门之间的数据往往以独立的方式分别存放。而伴随着金融科技新型业务的不断发展,跨部门、跨业务的数据访问成为企业的核心需求。但是,各业务系统独立存放的数据往往形成一个个“数据孤岛”,使得企业内部的数据管理面临极大的挑战。
彭旸表示,“巨杉数据库是第一个在行业内推动‘数据湖’概念的企业”。
新型分布式数据库的出现旨在打破传统数据管理的体系,将跨业务、多类型的数据进行统一的管理与维护,从数据的层面将企业内部的各个部门与业务线融会贯通。“数据湖”就是典型的一个行业应用。
以银行为例,传统金融企业有很多的业务和部门,很早以前每个部门以自己的业务驱动做一套产品,要查一个用户的个人资产,需要通过40个系统把数据取回来。因为每个业务的分支数据没有融合成一个大湖,银行每做一个操作都要通过40个系统,整个IT效率非常低下。
在将数据融合之后,跨业务的数据访问将变得非常容易,而全量的数据也可以保留全量的信息,帮助大数据系统更好的分析系统、公司整体运营的情况。
作为现在火热的区块链技术,也在BDTC 2017依托主会keynote和独立的分论坛而展示。这个去中心化的技术和中心化的数据库是否有着相悖的理念呢?它们之间如何结合?
彭旸解释说,区块链是多方产生数据,如银行和供应链、零售商。每个不同的个体都有相关业务体系的,区块链是无法把全部多方的业务体系放在区块链上。在区块链上做的更多是交易的结果,产生跟信用价值相关的东西,这些内容会沉淀到区块链体系。区块链是一个分布式网络,其顶层是各个不同的业务和中心,大家都有分布式数据库业务。只有数据量小,且要求不可篡改,大幅度提高信任等级的需求,企业才会把这方面的数据交给区块链来去做。
同样对于AI方面,分布式数据库可以作为机器学习很好的数据源,满足深度学习的高并发、高性能和大数据量的核心数据需求。而巨杉数据库目前全面支持对接Spark架构,Spark也将会很快开始推广他们的Spark MLlib等机器学习框架,我们也希望在机器学习支持方面取得更多突破。
最后,CSDN和彭旸谈到了大数据人才选型方面话题,他认为。国内许多年轻人总是“哪个技术行业火,就往哪里跑”,前端火,都去前端;大数据分析火,都做数据分析。现在这个风口也来到了AI人工智能领域。
对于大数据这块的基础软件,技术都有很强的延续性和行业积累在,因此团队基因很重要。对于人才,基础软件更需要技术的沉淀,要真正了解核心的大数据技术更是需要长期的积累和经验。
很多时候,年轻的新人会忽略很多基础的技术能力,如:操作系统、数据结构等。如果没有扎实的基础,新人很难去从整体理解理解项目脉络,“你总是在一片叶子上关注,是看不到整棵大树的”。彭旸说,巨杉数据库一直在招人,但应聘者会写Java的很多,懂底层c++的人才就太少了。因此也希望看到更多的年轻人去参与到基础技术中。
十年蜕变,历久弥新。自2008年第一届 Hadoop 中国云计算会议在中科院计算所举办至今,大数据技术大会已经走过了整整十年。大数据从技术概念逐步落地到行业场景,分布式数据库技术的发展满足了金融业在互联网时代的弹性、高可用性和成本的需求。
巨杉作为国内分布式数据库的一线技术提供商,成功入选 Gartner 数据库行业年度报告,着实令人振奋,CSDN 再次感谢巨杉数据库彭总从一线产业的角度给我们带来了未来大数据技术发展的思考。






