SequoiaDB 巨杉数据库 3.0,经过近半年在金融级场景的测试、上线和稳定运行之后,于近期正式发布。
SequoiaDB 巨杉数据库是一款金融级分布式数据库,包括了分布式 NewSQL、分布式文件系统与对象存储、与高性能 NoSQL 三种存储模式,分别对应分布式联机交易、非结构化数据和内容管理、以及海量数据管理和高性能访问场景。
根据 Gartner 的数据库报告,Multi-model多模是未来10年,下一代分布式数据库发展的最主要方向。从1.0的高性能分布式 NoSQL 数据库,到2.0加入的分布式对象存储,再到3.0完整协议级兼容MySQL,SequoiaDB 经过6年的不断迭代创新,全面支持企业级结构化、半结构化以及非结构化数据存储。
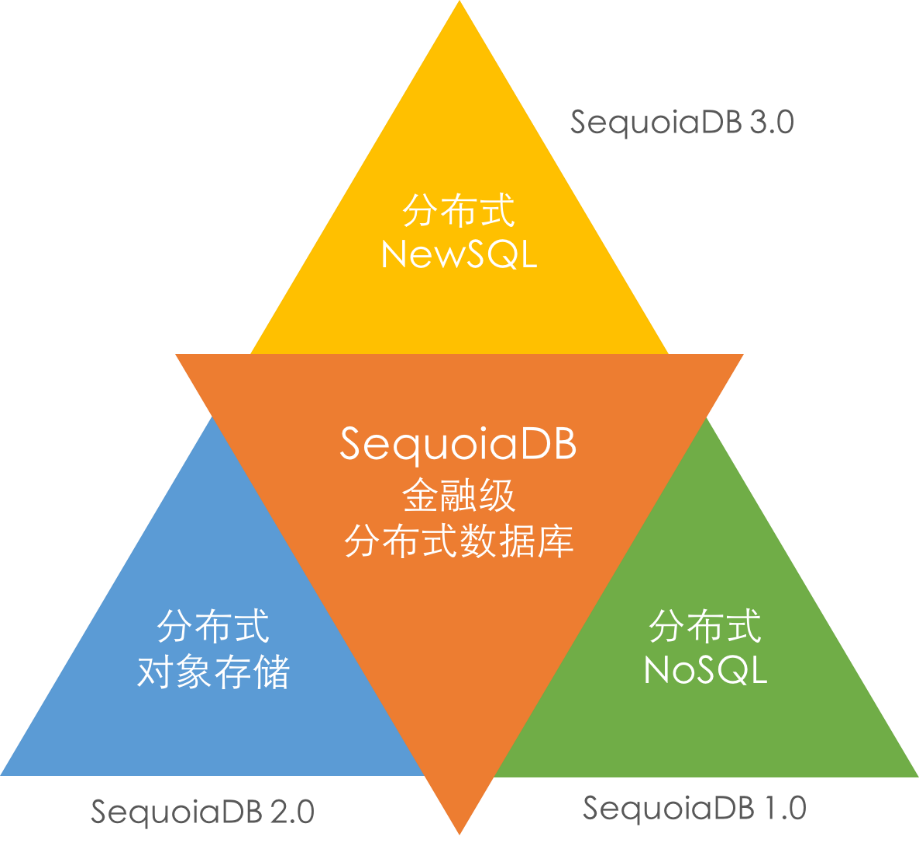
SequoiaDB 3.0 产品维度
SequoiaDB 3.0实现了100%的 MySQL 协议级兼容:
全面兼容:全面支持 MySQL 协议与语法,用户可以直接使用 MySQL 客户端或任何管理、开发与监控工具对数据库进行操作;
MySQL 语法:由于使用了 MySQL 原生的解析器,SequoiaDB 3.0 能够实现100%的 MySQL 语法兼容,支持语法包括基础 CRUD 操作,多表关联,跨节点事务操作,创建视图,存储过程,索引和访问计划等。
无缝切换: 对于任何已有应用程序,SequoiaDB 3.0提供全面的 MySQL 兼容,几乎无需应用程序代码调整,即可无缝切换;
分布式弹性扩展:通过 SequoiaDB 存储引擎原生分布式架构,数据库在兼容 MySQL 同时,无需“分库分表”,分布式存储引擎直接提供弹性容量扩展能力,可以上百倍提升应用程序的存储空间与访问性能;
表多维分区:通过存储-SQL分离架构,用户访问 MySQL 也可以实现表的多维分区,提升应用的灵活性。
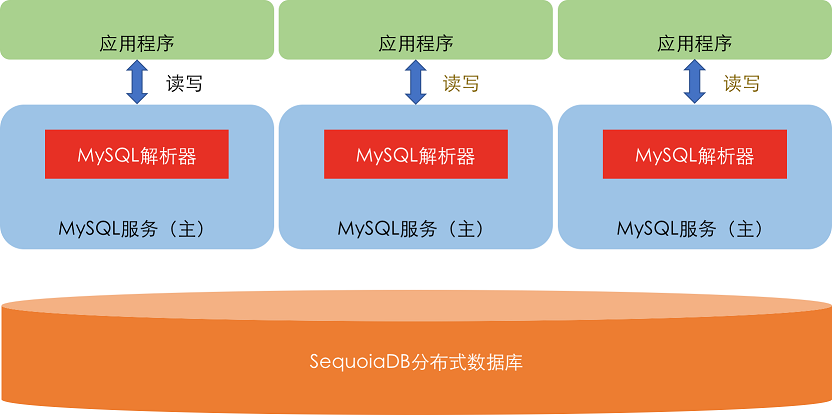
SequoiaDB 3.0 MySQL 兼容架构
SequoiaDB 3.0采用了“存储-SQL 分离”的架构,类似架构也出现在 AWS 的 Aurora 数据库等众多新一代分布式数据库上。
SequoiaDB 3.0使用了 MySQL 数据库原生的 SQL 解析器,天然支持 MySQL 协议并可以做到100%语法兼容。在该架构中,MySQL 协议解析层作为 SQL 解析和分发的角色,直接面对应用程序,每一个 MySQL 服务的接入节点都是一个独立支持读写操作的 MySQL 进程。而数据存储和管理层,则完全由巨杉数据库的分布式数据库引擎实现。简单来说,SequoiaDB 3.0作为 MySQL 的 InnoDB 替换引擎,在天然支持 MySQL 的全部语法和功能的同时,提供了数据库存储层弹性扩张的能力。
SequoiaDB 3.0 的 MySQL 兼容主要体现在 SQL 语法层面,而针对分布式 OLTP 业务的其他众多数据管理机制,均在 SequoiaDB 的分布式数据库引擎实现。
SequoiaDB 3.0 针对分布式 OLTP 业务,在分布式存储引擎方面带来了一些重要的提升:
ACID:
ACID是交易型数据库的基础,SequoiaDB 3.0已经全面支持 ACID,100%支持原子性、一致性、隔离性与持久性;
跨表跨节点事务:
在分布式数据库中,多节点间的原子性操作需要特殊的方式实现,SequoiaDB 3.0使用二段提交的方式支持跨表跨节点事务能力;
隔离性:
支持 read-committed 隔离级别;
锁机制:
SequoiaDB 内核对记录锁的管理进行了优化,完全避免了在大量并发交易时的锁拥堵问题;
CBO(Cost-Based Optimization)基于开销的优化:
实现对集合内的数据以及索引进行统计抽样,建立多维度、多层级的数据模型;并对外部查询语句进行“重写”、“规则优化”、“参数化”以及“谓词降解”优化,提升访问性能,这也是目前企业级数据库主流的优化器优化方式;
表压缩:
针对表级别的数据压缩,提供两种压缩方式,压缩比例最高超过60%,极大提升性能和吞吐量;
安全性:
分布式架构支持高可用与异地灾备机制,在提供一主多备存放的同时还支持读写分离模式。SequoiaDB 3.0原生支持两地三中心等异地容灾策略,保证交易数据安全可靠。
SequoiaDB 3.0在对象存储API的基础之上提供了标准 Posix 文件系统接口,能够原生接入任何支持 Posix 协议标准的操作系统,用户对应用程序无需任何改造即可从NAS迁移至 SequoiaDB。
在使用 Posix 文件系统的基础上,SequoiaDB 3.0完全避免了传统文件系统在存储大量文件时所产生的性能瓶颈。同时,得益于 SequoiaDB 的分布式架构,其对象存储与文件系统特性在对应用程序零改造的前提下,成百上千倍地提供了存储的扩展性以及并发吞吐能力。
在该版本中,还引入了‘偏移锁’机制,当并发操作同一个文件时,每一个并发只锁定其偏移内的内容,这样即可以保证并发情况下文件内容的正确性,极大程度提升了外部访问的并发度。
SequoiaDB 3.0支持全文检索能力。用户可以通过创建针对指定字段的全文检索索引,对字符串中的内容进行实时模糊匹配,达到像使用普通查询一样方面地使用全文检索功能。
在索引类型中,增加了新的‘全文索引’类型,用户只需要在对集合创建索引时指定为‘全文索引’类型即可以轻松地创建。在全文索引创建后,索引定义的内容会自动同步至全文索引引擎,之后新的数据变化也会快速同步至全文索引引擎中。
SequoiaDB 3.0支持异步全文索引,在高吞吐量的数据导入时不会对导入性能造成任何影响。
SequoiaDB 原生支持数据库内核级别的高可用以及跨数据中心灾备能力,不需要使用第三方工具即可使用多副本对数据进行保护,完全满足金融级要求:
数据中心内高可用安全:RPO、RTO为0,迅速响应无缝切换;
异地容灾:异地容灾和备份,保证数据安全,中心间距离超过1000km以上。满足“两地三中心”的监管需求;
同城双活:同城双中心的数据实时同步,保证数据一致;双中心数据可以实现同时读写,大大提升读写效率;中心切换RPO 为0 ,RTO 小于 1分钟;
更便捷的灾备管理:系统集群中统一管理灾备中心,简化了维护成本,也帮助使用者更快上手。
SequoiaDB 3.0 在性能方面也有持续提升。通过 Sysbench 标准测试,SequoiaDB 3.0 性能表现优秀。测试主要考察三种场景,插入、查询以及交易事务几项基础数据库操作指标,以下为相关的测试方法以及结果:
Insert:单条数据插入
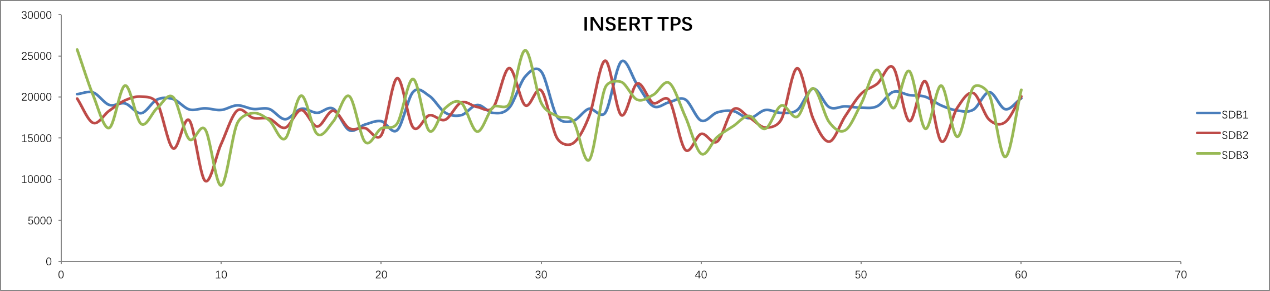
启动3个96并发运行 Insert 的 Sysbench 进程30分钟,SequoiaDB 测试结果:平均响应时间为5.28ms, TPS为54,513.58笔/s,成功率为100%。
Select:索引查询,精确匹配中一条记录
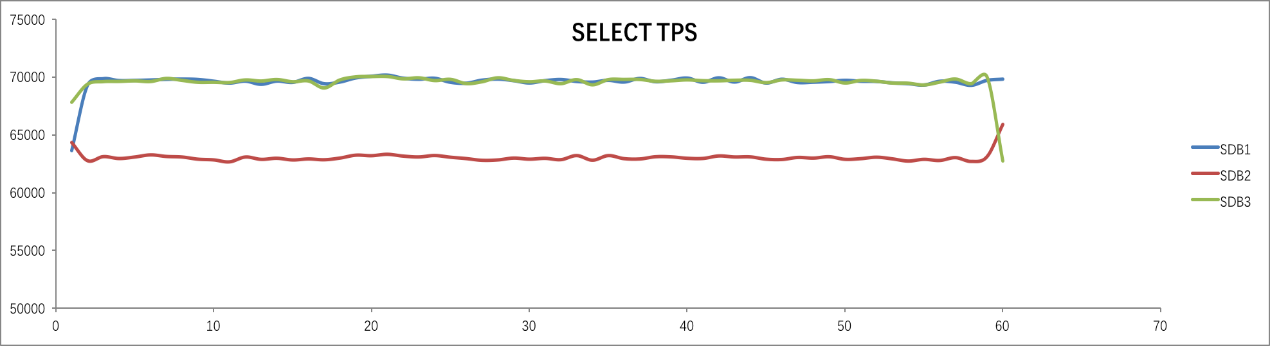
启动3个96并发运行 Select 的 Sysbench 进程30分钟,SequoiaDB 测试结果:平均响应时间为1.42ms, TPS为202,886笔/s,成功率为100%。
OLTP事务操作:
一个 OLTP 事务包括10个精确索引匹配查询,1个索引范围查询,1个索引范围查询汇总,一个索引范围查询排序,一个索引范围查询去重,一个精确匹配更新索引字段,一个精确匹配更新非索引字段,一个精确匹配删除,一个单条记录插入(主键为删除记录字段的值)。
启动3个96并发运行 OLTP 的 Sysbench 进程30分钟。
SequoiaDB 测试结果:平均响应时间为68.74ms,TPS为4,198.29笔/s,成功率为100%。
SequoiaDB 3.0 目前已经在金融行业的企业用户准联机业务和众多的实时联机交易场景投入使用。经过金融级联机业务的考验,SequoiaDB 3.0 将会在未来拓展至更多行业应用场景,成为比肩国际巨头的中国分布式数据库产品。






