近期,艾瑞咨询首次发布中国数据库行业研究报告。《2021年中国数据库行业研究报告》梳理了各种类型数据库的技术架构和适用场景,从供需双方视角分析了中国数据库市场的存量挑战与未来趋势。本文将根据报告中提到的多模数据库进行介绍和分析。

多模数据库现状及其局限
面对多类型的的结构化、半结构化和非结构化数据,现代应用程序对不同的数据提出了不同的存储要求,数据库因此也需要适应这种多类型数据管理的需求。《2021年中国数据库行业研究报告》的第一章将数据库按数据结构,分为传统关系型数据库、NoSQL数据库、NewSQL数据库和多模数据库。为了实现业务数据的统一管理和数据融合,数据库需要具备多模(Multi-Model)数据管理和存储的能力。
该报告中提到,“多模数据库是一种可以在多个模型中存储和查询数据的数据库,为异构数据提供了较好的解决方案。数据库扩展原有模型的路径主要有四种:新存储方式+新数据模型、原存储方式+新数据模型、新接口+原存储模型、原存储模型”。四种典型代表数据库及扩展路径见下图。但是目前市场上数据库对多模的支持程度不同,“在数据模型、索引、多模查询优化策略等方面的能力参差不齐。”

图片来源:艾瑞咨询《2021年中国数据库行业研究报告》
另外,《2021年中国数据库行业研究报告》中还提到,“面对业务形态多样、商业模式多变、需求变化频繁的当代市场,数据库和应用系统存在的形式也愈发的丰富,这也对数据迁移和多库管理提出新的挑战。一个企业往往拥有多个系统,从本地到云端,从关系型到非关系型,从OLTP到OLAP,从国外品牌到国产品牌,数据库之间的跨库查询、数据导出迁移、结构变更等操作已成为常态。数据迁移频繁、多库并存的现状,使得企业后期的使用成本(运维成本、人力成本、多技术栈学习成本、迁移成本、二开成本等)大幅提高,也为数据库厂商提出了“统一管理”的新挑战。”
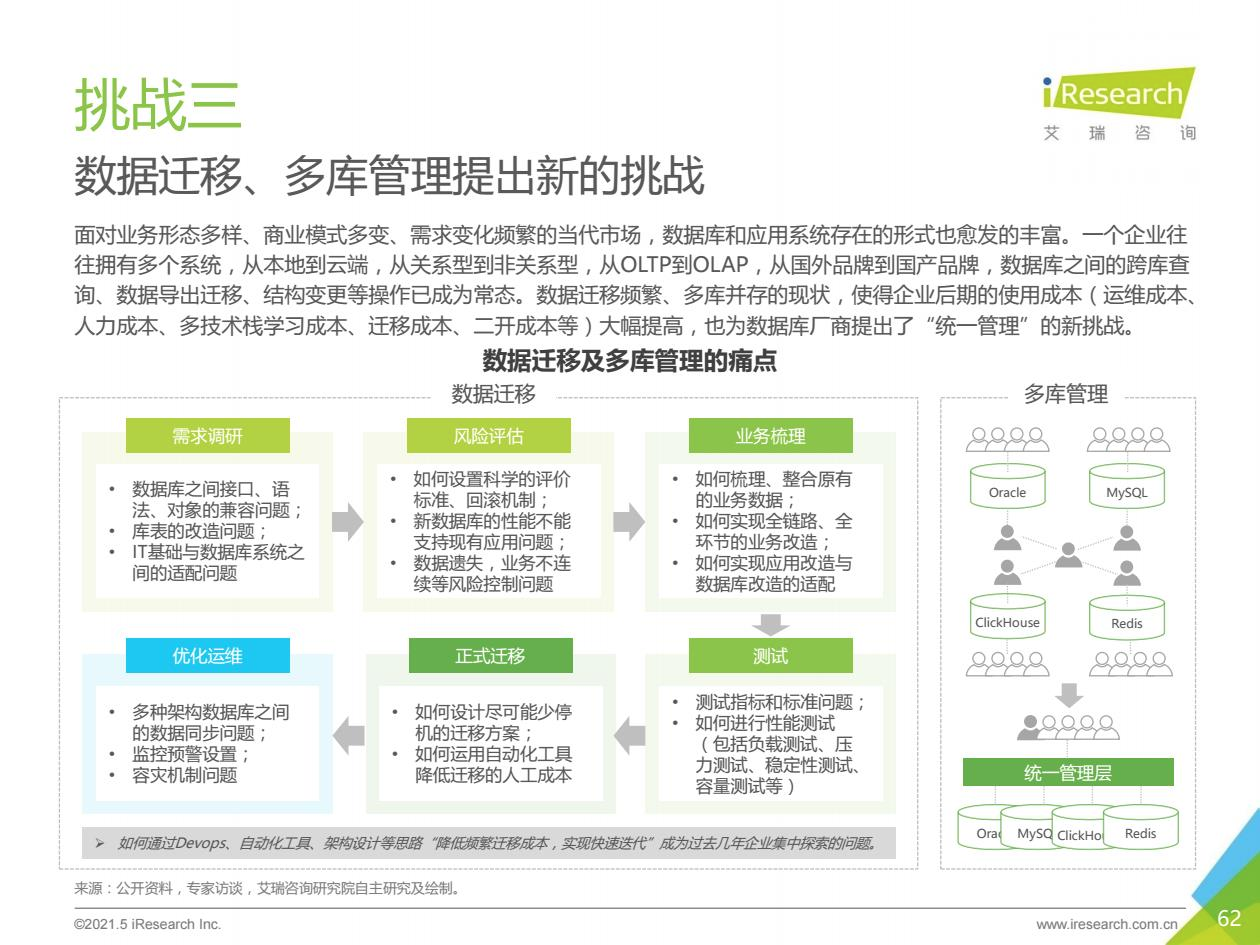
图片来源:艾瑞咨询《2021年中国数据库行业研究报告》
而随着中台、微服务的架构的兴起,开发人员也面临新的问题。基于微服务架构理念,不仅前端和逻辑层组件需要拆分,数据库本身也需要拆分。这将导致两个微服务进行数据交互时,若使用API接口模式,通过上层应用保证数据一致性,或通过异步ETL方式进行数据同步,为另一服务聚合出新的数据内容。不管是使用哪个方案,都必将导致数据管理变得复杂,同时导致数据延迟,影响业务性能。而且,由于需要处理的数据在各个独立数据库中单独保留,容易形成数据孤岛并导致大量数据冗余,浪费系统空间。

巨杉数据库:引擎级多模架构实现一库多用
针对上述多模数据库的局限性,巨杉数据库在存储数据结构方面进行创新。对于结构化和半结构化数据,SequoiaDB 在数据库内部使用 BSON 格式来将结构化及非结构化数据以文档的形式存储在集合中。而对于非结构化数据,SequoiaDB使用大对象(LOB)进行管理,在内部将 LOB 数据抽象为元数据和数据本身。通过独创的引擎级多模架构,巨杉数据库能够实现一库多用和跨引擎 ACID 事务一致性。
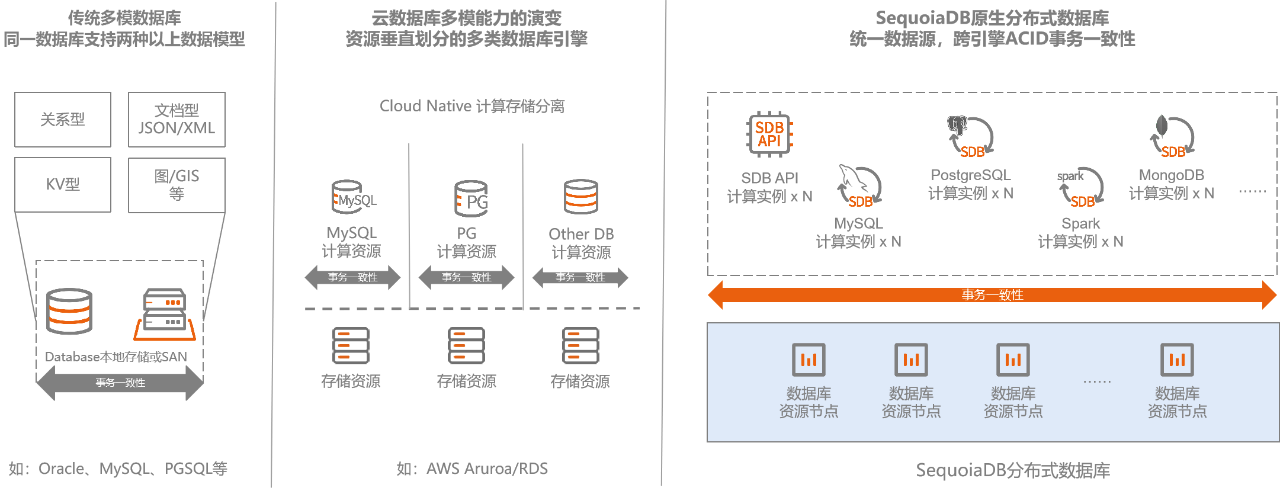
与众多云原生数据库一样,巨杉数据库提供存储计算分离云服务架构,并支持在此架构上构建包括:MySQL、PostgreSQL、Spark等多种数据库引擎。客户可以灵活选择需要的数据库引擎,实现无须代码修改的平滑迁移。但不同的是,巨杉数据库底层并非构建于一个简单的分布式存储,或计算资源平台。巨杉数据库底层是一个完整的分布式数据库,具备完整的事务一致性、排序过滤和下推计算等能力。而上层计算实例层只承担SQL或API解析及业务计算的工作,所以不同引擎下发的操作,事务一致性在分布式数据库底层进行控制。
基于「引擎级多模」能力,MySQL及MongoDB可以同时挂载相同的SDB数据域,即可实现不同的数据引擎共享同一个数据域的数据,实现实时共享的读写处理,无须任何数据异构导入操作,因此也不会导致因数据异构导入带来的数据延迟问题及数据冗余空间浪费。同时,研发人员可以直接将原有的MySQL或MongoDB应用直接跑在SequoiaDB中,无须因为使用新的数据库而进行程序修改。可以说,巨杉数据库的多模架构有效解决了上文中提到的多模数据库所面临的局限性和问题。
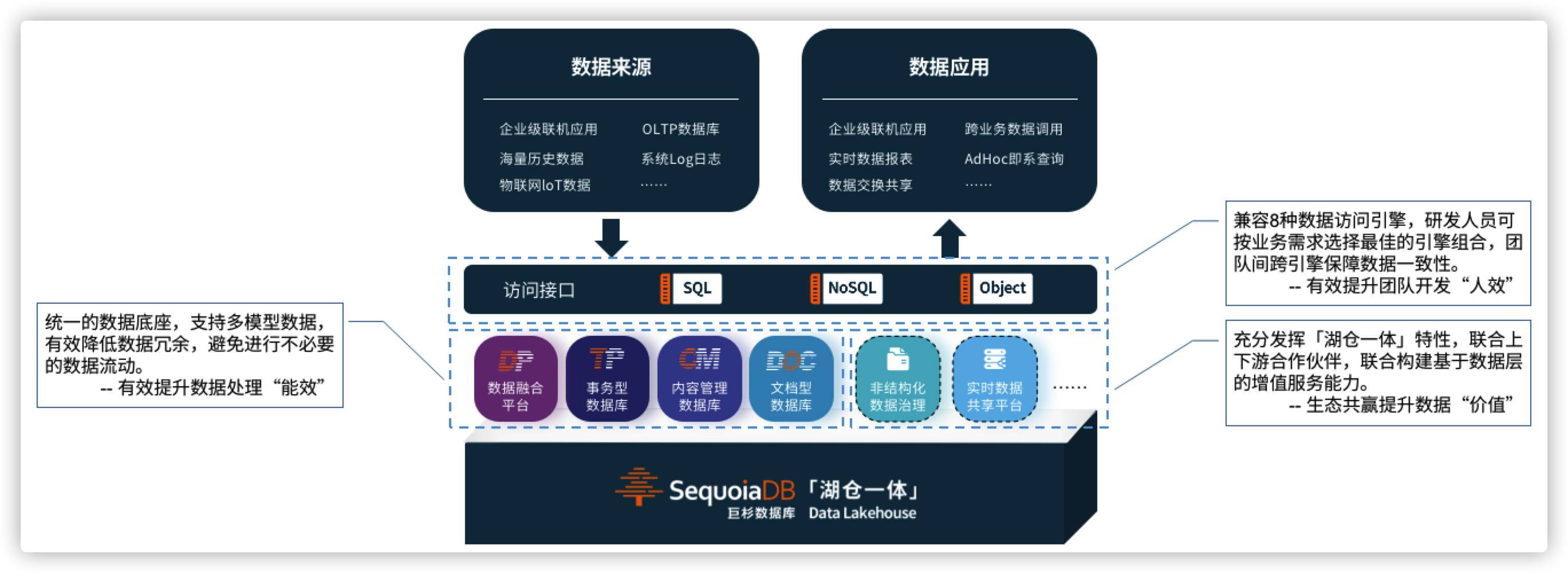
在巨杉数据库的典型应用架构中,企业通常基于其产品「湖仓一体」和「多模」的架构特性,以及巨杉数据库100%自研原生分布式数据库内核的“联机数据湖”能力,构建统一的数据基础设施平台,以整合以往分散管理的结构化SQL、半结构化NoSQL和非结构化Object数据。
目前, 巨杉数据库充分兼容包括:MySQL、MariaDB、PostgreSQL、Apache Spark、S3、NAS、SDB API在内的8种接口,以协助企业客户及开发者实现与现有架构的平滑迁移。其特有的跨引擎事务一致性能力,可以有效简化多团队开发流程中对不同引擎及结构的ACID管理,提升业务开发、数据处理、运维管理多方面提升企业的综合数据管理效率,为金融级对数据一致性要求极高的行业提供数据中台及微服务架构下的最佳分布式数据库应用实践。






