SIGMOD数据管理国际会议(Special Interest Group on Management Of Data.)是由美国计算机协会(ACM)数据管理专业委员会(SIGMOD)发起、在数据库领域具有最高学术地位的国际性学术会议,所收录的论文代表了行业内的最高水平。会议的目的是在全球范围内为数据库领域的研究者、开发者以及用户提供一个探索最新学术思想和研究方法、交流开发技巧、工具以及经验的平台,引导和促进数据库学科的发展。
SIGMOD第一届会议于1974年在美国密西根(Michigan)召开,传统上一直都在北美内部举办。自2004年在巴黎举办起,逐步开始走向国际。值得一提的是,第26届ACM SIGMOD国际数据管理学术会议曾在2007年在北京国际会议中心举行,当时的会议受到国家自然科学基金委员会国际合作交流项目资助,由ACM SIGMOD主办、清华大学承办。这是该会议第一次在亚洲举行、也是第二次在北美以外的国家举行。也是在这一年,中国人民大学信息学院李翠平教授作为第一作者发表了中国大陆第一篇SIGMOD论文。
时隔14年,2021 SIGMOD大会再度回归中国,于6月20-25日在西安举办。SIGMOD顶级学术会议对促进数据库领域学者和开发者开展更深层次的国际交流与合作,进一步提高我国数据库领域的研究水平有重要作用。华为和巨杉数据库作为中国企业,以最高钻石赞助级别与微软共同赞助本次SIGMOD大会和编程大赛。

同时,SIGMOD大会、SIGACT和SIGART联合,赞助了关于数据库系统理论方面的年度ACM数据库系统原理研讨会(PODS)会议。SIGMOD/PODS两个会议于1991年在美国丹佛(Denver)首次联合召开,这次联合举办会议的尝试取得了巨大成功,鼓舞了整个数据库界理论和系统的结合。之后SIGMOD会议和PODS会议都是同时举行。每年,该小组都会对在数据管理领域做出的贡献颁发多个奖项。其中最重要的是SIGMOD Edgar F. Codd创新奖(以计算机科学家Edgar F. Codd的名字命名)。1970年,在IBM工作的计算机科学家Edgar F. Codd发表了一篇名为“A Relational Model of Data for Large Shared Data Banks”的论文,该论文中正式提到关系数据模型,可以说就此开启了关系型数据库难以撼动的黄金时代。Edgar F. Codd于1981年获得计算机界最高奖图灵奖,是第一位获得图灵奖的数据库学者。2003年离世后,为了纪念他对于数据库领域做出的卓越贡献,2004年,SIGMOD将大会最高奖的名称改为SIGMOD Edgar F. Codd创新奖。该奖项旨在鼓励“数据库系统和数据库的开发,理解或使用具有持久价值的创新性和高度重要的贡献”。此外,SIGMOD还会颁发“最佳论文奖”,以表彰每次会议上质量最高的论文,并授予“吉姆•格雷论文奖”,表彰在数据管理方面的最佳博士学位论文。

由于数据库是一门侧重工程的实践类科学,因此学术会议SIGMOD也开始逐渐重视学术界和工业界的合作交流。自2018年起,SIGMOD增加了专门的Industry session。因此,近几年的大会流程通常包括:主题演讲(Keynote Talks),学术报告会(research session)和工业报告会(industry session),同时安排了Workshop、教程演示、研讨会和学生研究竞赛等环节。演讲内容涵盖范围非常广泛,除了传统的交易、存储和索引、查询处理和优化,云和分布式数据库,事务处理等,还涉及到前沿的数据湖和数据仓库、图数据、机器学习和分析、空间数据、数据挖掘和可用性分析、隐私安全和区块链等方面的内容。
近年来,Research Session的论文接收率为17-20%左右,Industrial Session的论文接收率在30%左右。据统计,SIGMOD 2020接收的学术论文共144篇,涵盖数据库领域多个领域,其中以第一作者单位为中国高校(清华大学、北京邮电大学、复旦大学和香港科技大学等)发表的文章共有21篇,大陆高校发表的文章为13篇,约占所有接收研究论文的9%。同时,我们注意到,自2015年开始,SIGMOD大会的最佳论文及最高创新奖项得主不乏华人学者和行业领军人物,例如以阿里、腾讯为代表的厂商以及各大高校的专家学者。
整体来看,在Industrial Session中,涉及传统关系数据库的创新成果正逐年减少,大部分研究工作均是多个领域交叉的成果。与此同时,国内数据库厂商在数据库研究中的参与度越来越高,国产数据库及相关技术在国际数据库领域的地位逐年攀升。中国新一代数据库在大规模企业应用中的实践经验,以及在湖仓一体、云化部署数据库方面的技术创新,在数据库行业中备受关注,也代表中国在数据库国际性学术会议中已占据非常重要的席位。
在2020年的SIGMOD大会中,有多个场次的主题演讲均涉及数据湖和数据仓库在企业当中的运用,例如,Databricks发表了有关建立有效的数据湖所面临的挑战的keynote, 来自宾夕法尼亚大学的学者介绍了在数据湖中查找相关表以进行交互式数据科学的研究成果。作为现代分析和数据科学的数据基础结构,数据湖开始在企业应用中普及并迅速增长。云存储与快速灵活的处理相结合,为构建分析应用程序提供了一种廉价且可扩展的解决方案。尽管数据湖使提取和存储大量数据变得容易,但是有效利用这些数据的能力仍然受到限制。这些数据通常缺乏上下文,不能满足应用程序所需的质量,并且用户不容易理解或发现。数据一致性和准确性问题使得很难从数据湖中获取价值,也很难信任基于此数据的分析。而在数据仓库层面,大会中的研究提到,日常业务运营和来自不同IoT应用程序的传感器等各种来源不断产生大量数据。它们通常被加载到数据仓库系统中以执行复杂的分析。但是,如果查询涉及联接,尤其是在多个大表上的多对多联接,可能会非常昂贵。由于数据仓库的存储格式以结构化为主,并且历经加工清洗,数据形态显得更加范式化、模型化,因此数据的灵活度较低。
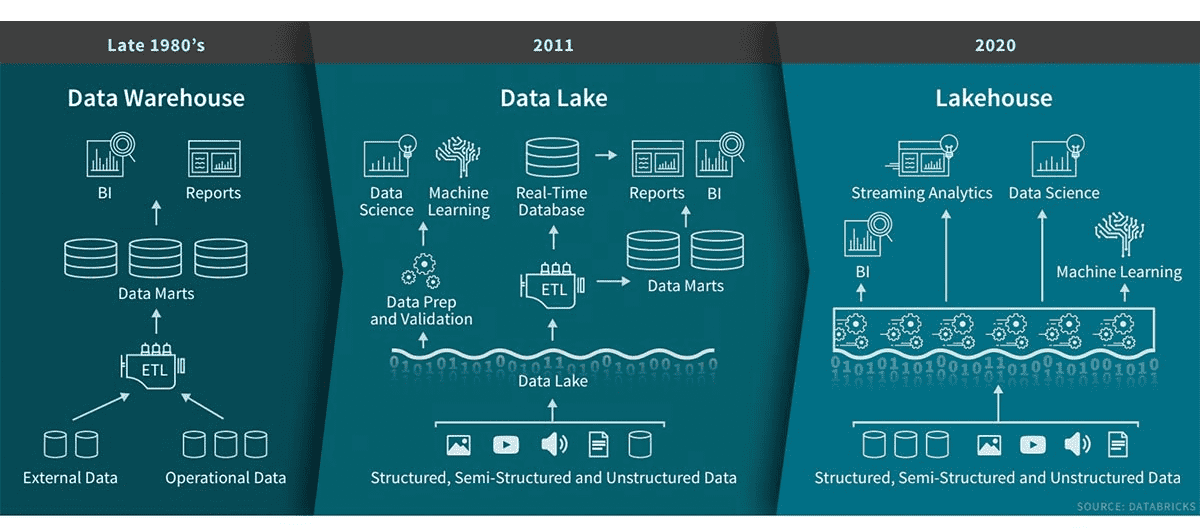
学术界逐渐意识到传统的“湖仓分离”模式所存在的局限性,企业在数据运营、价值挖掘、运维等方面,也遇到了显著的挑战。因此,业界提出了湖仓一体(Data Lakehouse)的概念,旨在为企业提供一个统一的、可共享的数据底座,避免传统的数据湖、数据仓库之间的数据移动,将原始数据、加工清洗数据、模型化数据,共同存储于一体化的“湖仓”中,既能面向业务实现高并发、精准化、高性能的历史数据、实时数据的查询服务,又能承载分析报表、批处理、数据挖掘等分析型业务。湖仓一体方案的出现,能够帮助企业构建起全新的、融合的数据平台,打破了数据湖与数据仓库割裂的体系,在架构上将数据湖的灵活性、数据多样性以及丰富的生态,与数据仓库的企业级数据分析能力进行融合。通过对机器学习和AI算法的支持,实现数据湖+数据仓库的闭环,极大地提升业务的效率。数据湖和数据仓库的能力充分结合,形成互补,同时对接上层多样化的计算生态。毫无疑问,湖仓一体将会更好地服务于企业,帮助企业实现大数据能力的提升,如降低成本、提升运营效率、业务模式探索等。今年SIGMOD大会钻石赞助商之一巨杉数据库,也基于湖仓一体架构,针对不同的业务需求场景细分出四大产品线。面向联机数据中台、历史数据服务平台、IoT物联网等海量数据需求场景,为企业级客户打造数据平台的最佳底座。作为数据基础设施,巨杉数据库湖仓一体架构的价值在于打通不同业务类型、不同数据类型之间的技术壁垒,实现交易分析一体化、流批一体化、多模数据一体化,最终降低数据流动带来的开发成本及计算存储开销,提升企业的运作的“人效”和“能效”。






